GPT 架构
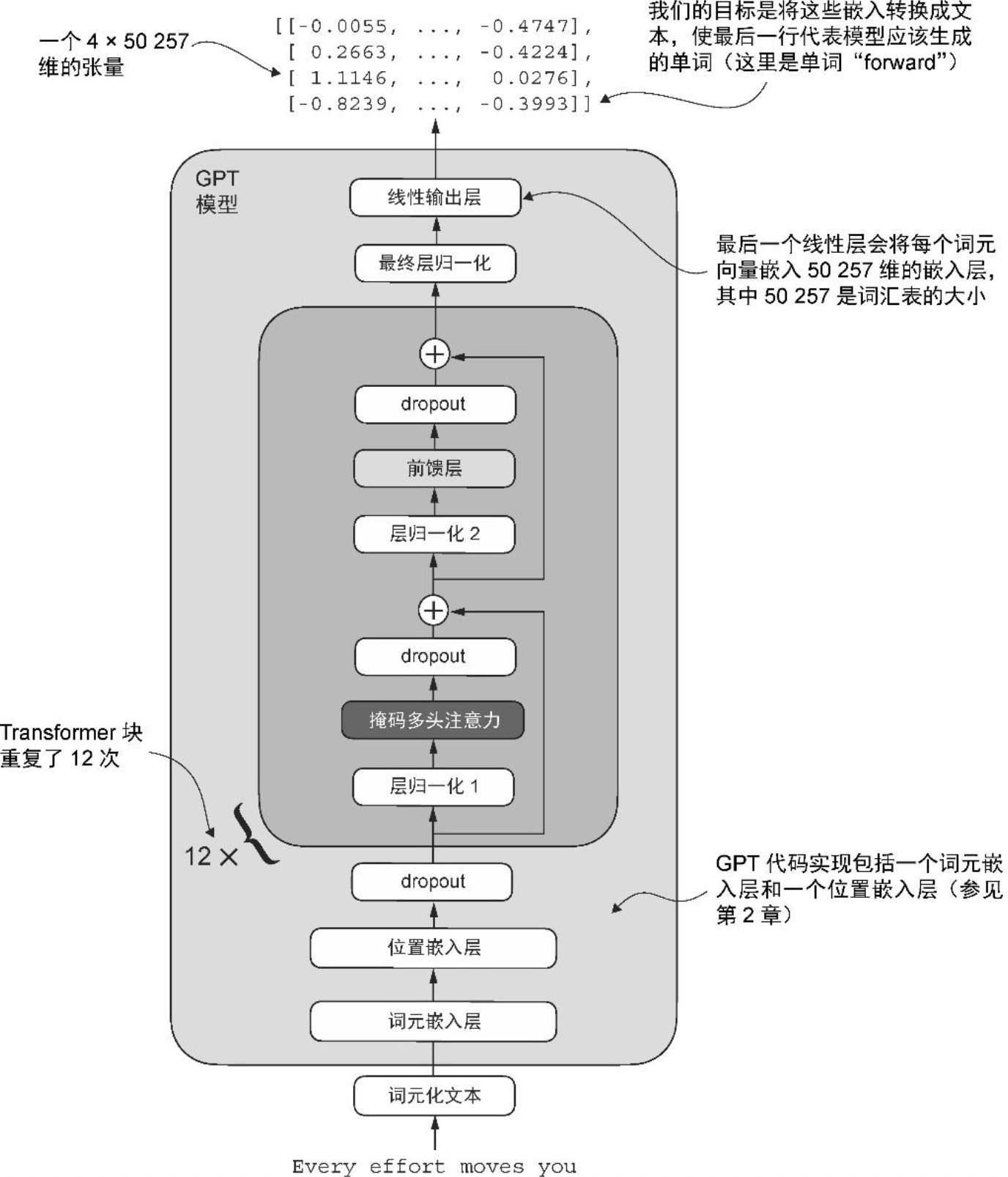
各步骤实现
前置准备
数据集
天龙八部纯文本
with open('tianlongbabu.txt', 'r') as f:
text = f.read()
# print(text[:1000])分词器
chars = sorted(list(set(text)))
# print(chars)
vocab_size = len(chars)
# print(vocab_size)
char_to_index = {ch: i for i, ch in enumerate(chars)}
index_to_char = {i: ch for i, ch in enumerate(chars)}
def encode(text):
indexes = []
for ch in text:
indexes.append(char_to_index[ch])
return indexes
def decode(indexes):
chars = []
for index in indexes:
chars.append(index_to_char[index])
return ''.join(chars)
# print(encode('段公子'))
# print(decode(encode('段公子')))训练数据/测试数据
import torch
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9 * len(data))
train_data = data[:n]
val_data = data[n:]训练参数
block_size = 128
dim_size = 128
dropout = 0.1
layer = 4
n_head = 4
head_size = dim_size // n_head
device = 'mps'
max_iter = 10000
learning_rate = 1e-3
batch_size = 64
eval_freq = 500
eval_iter = 100模型架构
先把主要框架搭起来
class GPTModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, dim_size)
self.position_embedding = nn.Embedding(block_size, dim_size)
self.blocks = nn.Sequential(*[Block() for _ in range(layer)])
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(dim_size)
self.linear = nn.Linear(dim_size, vocab_size)
def forward(self, indexes):
# 词元嵌入层 (B,T,C)
token_emb = self.token_embedding(indexes)
# 位置嵌入层 (T,C)
position_emb = self.position_embedding(torch.arange(indexes.shape[-1], device=device))
emb = token_emb + position_emb
# 对 embedding 的特征维度 dropout,随机将部分元素置零,以防止过拟合
emb = self.dropout(emb)
# 堆叠的 Transformer 块 (B,T,C)
x = self.blocks(emb)
# 最终层归一化
x = self.ln(x)
# 线性输出层,输出每个位置上每个词的 logits,即未归一化的概率分布
logits = self.linear(x) # (B,T,vocab_size)
return logitsTransformer 块
class Block(nn.Module):
def __init__(self):
super().__init__()
self.ln1 = nn.LayerNorm(dim_size)
self.multiHeadAttention = MultiHeadAttention()
self.ln2 = nn.LayerNorm(dim_size)
self.ff = FeedForward()
def forward(self, x):
x = self.ln1(x) # 层归一化 1
x = self.multiHeadAttention(x) # 多头注意力
x += x # 残差连接
x = self.ln2(x) # 层归一化 2
x = self.ff(x) # 前馈层
x += x # 残差连接
return x多头注意力
这里做了两种实现:一种按 head 分别计算 QKV,逻辑更直观; 另一种将所有 head 的 QKV 通过一次线性变换统一计算,并并行完成注意力运算,以提升效率。
实现一:分别处理
class MultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
self.heads = nn.ModuleList([Head() for _ in range(n_head)])
self.linear = nn.Linear(dim_size, dim_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 每个头分别处理后进行拼接
x = torch.cat([head(x) for head in self.heads], dim=-1)
# 输出投影层,让各 head 的特征发生交互
x = self.linear(x)
x = self.dropout(x)
return xHead
class Head(nn.Module):
def __init__(self):
super().__init__()
self.q = nn.Linear(dim_size, head_size, bias=False)
self.k = nn.Linear(dim_size, head_size, bias=False)
self.v = nn.Linear(dim_size, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
# 计算 q、k、v
q = self.q(x)
k = self.k(x)
v = self.v(x)
# 缩放点积自注意力
# q、k 的点积是 head_size 个随机变量之和,其方差约为 head_size,标准差约为 sqrt(head_size),
# 由于其数值随维度线性增长,太大的数值会导致 softmax 函数过于尖锐,梯度变小,难以学习,
# 因此除以 sqrt(head_size) 将标准差重新拉回 1,将数值尺度重新归一化到稳定范围。
atten = q @ k.transpose(-2, -1) * k.shape[-1] ** -0.5
# 对未来的词掩码
# self.tril[:T, :T] 是因为 T 可能小于 block_size
atten = atten.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
atten = F.softmax(atten, dim=-1)
# dropout 防止过拟合
atten = self.dropout(atten)
return atten @ vFeedForward
在每个 token 内对特征进行高维展开、非线性变换和再压缩,从而让模型能够学习复杂模式。
class FeedForward(nn.Module):
def __init__(self):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(dim_size, dim_size * 4),
nn.ReLU(),
nn.Linear(dim_size * 4, dim_size),
nn.Dropout(dropout)
)
def forward(self, x):
return self.mlp(x)实现二:合并处理
经试验,在特定参数下可比实现一快 2-3 倍。
class CausalSelfAttention(nn.Module):
def __init__(self):
super().__init__()
# 将用于生成 Q、K、V 的三个 (dim_size, dim_size) 的权重矩阵拼接为
# 一个 (dim_size, 3 × dim_size) 的矩阵,对输入一次线性变换即可同时
# 得到 QKV,再按维度切分,从而减少计算次数、提高效率。
self.attn = nn.Linear(dim_size, dim_size * 3)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.attn_dropout = nn.Dropout(dropout)
self.linear = nn.Linear(dim_size, dim_size)
self.resid_dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
# 一次性计算完 QKV 再切分
q, k, v = self.attn(x).split(dim_size, dim=2) # (B,T,C)
# 将 QKV 的最后一维从 dim_size reshape 为 (n_head, head_dim),
# 再将 head 维度提前,从 (B,T,n_head,head_size) 转为 (B,n_head,T,head_size)
# 从而得到按 head 划分的 Q、K、V。
q = q.view(B, T, n_head, head_size).transpose(1, 2) # (B,n_head,T,head_size)
k = k.view(B, T, n_head, head_size).transpose(1, 2) # (B,n_head,T,head_size)
v = v.view(B, T, n_head, head_size).transpose(1, 2) # (B,n_head,T,head_size)
# (B,n_head,T,head_size) x (B,n_head,head_size,T) = (B,n_head,T,T)
attn = (q @ k.transpose(2, 3)) * q.shape[-1] ** -0.5 # (B,n_head,T,T)
attn = attn.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
attn = F.softmax(attn, dim=-1)
attn = self.attn_dropout(attn)
# (B,n_head,T,T) x (B,n_head,T,head_size) = (B,n_head,T,head_size)
y = attn @ v
# 将各个头的输出进行拼接
# (B,n_head,T,head_size) transpose => (B,T,n_head,head_size)
# view => (B,T,C)
y = y.transpose(1, 2).contiguous().view(B, T, C) # (B,T,C)
# 输出投影层,融合各个 head 的特征
y = self.linear(y)
# dropout 防止过拟合
y = self.resid_dropout(y)
return y训练
待补充
生成文本
待补充
效果
generate(‘慕容’)
慕容复,实则是惊讶,不知这门功夫多了得,倘若我跟你说去,咱们出去,人家比试试试?”他说到这里,突然双膝一软,叫道:“这是你的,倒也不用一招。”虚竹却道:“我……我……我……我的武功是解不透。我……你别说,我……我……我向来……有说……没良久,我
generate(‘段公’)
段公子,你去请王姑娘。”段誉道:“不!我也不信!”心中一动,只见王语嫣是一个女子,喜道:“段郎,你怎可说得上是她容貌美丽的女子?你们又扮了这个男人,你是谁?”段誉强忍不住笑道:“我妈,你就是你的孩儿,如不肯娶我,难道你不
pytorch 知识点
- nn.ModuleList
- register_buffer
- transpose
- torch.tril
- torch.stack/torch.cat
- masked_fill
- split
- view
- contiguous